

Data mining is not an isolated area of study. It is highly related to many others under the big umbrella of Big Data and Data Science. So let's talk about it in the context of these terms.
Big Data
McKinsey Report (2011):
Big Data is data whose scale, distribution, diversity, and/or timeliness require the use of new technical architectures and analytics to enable insights that unlock new sources of business value. ”
and:
There will be a shortage of talent necessary for organizations to take advantage of big data.
The McKinsey report has had a huge impact on the evolution of related fields. Since the report, there has been rapid growth in the number of industrial positions and academic programs motivated by the term "Big data."
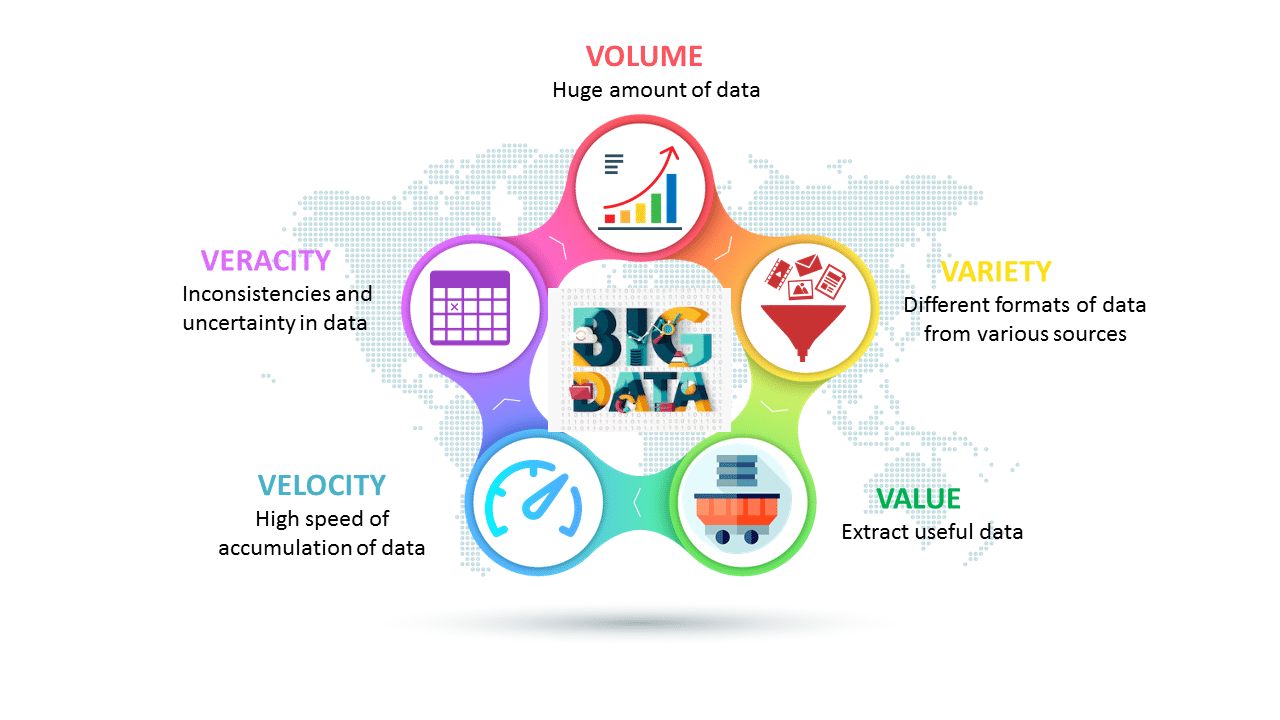
This is certainly not a fad purely driven by a report. They have been driven by real challenges and opportunities due to data. In particular, the Vs explain why data are both challenging but potentially rewarding.
Look at the sheer volumes of data we generate and consume; the variety of them in so many different forms and formats; and the velocity or speed at which they arrive and depart. Is that fascinating, and a bit intimidating, for those of us who want to get hold of them?
Besides, it is also the time of fake news. What value do your data provide? Perhaps it does not mean a lot in its raw forms; but what about your analysis? Can you actually identify truthful insight and add important value?
Related to:
- Computer Science and Information Science
- Machine Learning and Artificial Intelligence
- Statistics, Data Mining, Information Retrieval, among others
These are critical questions, questions that cannot be answered with a narrow mind but should be tackled by a joint effort. That is why related approaches to these challenges do not come from a single discipline, but many. And these include computer science and information sciences, machine learning and AI, as well as methods from statistics, data mining, information retrieval, and many others under the umbrella of data science.
According to Dhar (2013):
Data science is an inter-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data
Data Science is an umbrella term that covers a wide spectrum of scientific disciplines.
- Traditional business intelligence to data science
- Structured data to unstructured data
- Ad hoc reporting to predictive modeling
- With machine learning and data mining
- Basic statistics to complex, contextual questions
There has been an evolution from traditional business intelligence to today's notion of data science; from the focus of highly structured data (even relational data) to unstructured data such as text, images, and human languages; from ad hoc reporting that is driven by human executives to predictive modeling that is driven by, data.
Now, our focus has shifted from basic statistics and hypothesis tests to answering more complex contextual questions.
- Analytics 1.0: Business Intelligence, data secondary
- Analytics 2.0: Big Data the turning point
- Analytics 3.0: Data Economy, data are the business
Some refer to this as the evolution from Analytics 1.0, which is focused on business intelligence where data is secondary; to Analytics 2.0 with big data as the turning point; and to Analytics 3.0 of the data economy, where the business is about data.
Data is the business.

This represents a paradigm shift. As Jim Gray suggests for scientific discovery, Data is the fourth paradigm. Over the history of science, we have evolved from the paradigm of empirical description to theoretical generalization, to computational modeling, and now, to a new paradigm based on data exploration.
Han and Micheline (2011), Knowledge Dicovery from Data (KDD):
Extraction of interesting patterns or knowledge from huge amount of data
Interesting means: non-trivial, implicit, previously unknown and potentially useful.

Data mining is well suited for this paradigm shift. In fact, from the beginning, it was designed for the new paradigm.
In classic statistics, for example, you were to come up with a hypothesis independent of data and only use the data to find out whether your hypothesis is true or false. You were not supposed to fish potential hypotheses by mining the data.
In today's paradigm of the data, however, there have been applications where the pure objective is to mine, generate, and validate hypotheses -- IBM Watson's participation in the Jeopardy is such an example, an example of text search and mining.
Constructing hypotheses is one way to represent human knowledge, in a true vs. false statement.
According to Han and Micheline (2011), data mining is the extraction of interesting patterns or knowledge from a huge amount of data. Interesting meaning: it is nontrivial, implicit, previously unknown and potentially useful.
In essence, this is to discover insight and knowledge from data. Data mining is often referred to as KDD, or knowledge discovery from data. Alternative names: knowledge discovery in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence...
Data Mining is an important field in Data Science:
- Data Science is about Science, the acquisition of knowledge
- Data Mining's objective is about knowledge (or insight)
- But Data Mining is not a lone field, as it uses methods from:
- Probability, information theory, and statistics
- Machine learning, information retrieval, natural language processing...
Data mining is an important field in Data Science with its objective for knowledge or insight. And data science is about "science," or the acquisition of knowledge by definition. It is associated with many fields such as statistics, machine learning, information retrieval, natural language processing, among others.

Overall, a data mining project involves such steps as data cleaning, integration, selection, transformation, mining, pattern evaluation, and finally knowledge representation.
- Importance of each step, in the context of data
- It may take iterations to discover useful insight
- It may requires various expertise, including domain knowledge
For example:
- data cleaning can be critical
- "Dirty data" being a major issue in many data science projects

It is important to recognize that the importance of each step depends on the data and objectives. This is a lifecycle of multiple iterations until useful insight can be drawn from data, and it may require different expertise and domain knowledge to guide the process and interpret discovered patterns or knowledge.
Many types of data can be treated as an input for data mining. Your data might be structured relational data or unstructured text data; static structural data, or temporal time series; homogeneous data, or heterogeneous data from different sources, collected from the web.
Data Mining Functions (Output)
- Generalization: integration, aggregation, summariation, etc.
- Association and correlation analysis: frequent patterns, rules
- Classification: training and testing (predictions)
- Cluster analysis: major patterns, themes, discovery of new categories
- Outlier analysis: outliers, noise or exception
- Sequence, trend and evolution analysis
- Graph mining, network analysis, web mining, etc.
The output of data mining is knowledge representation, insight or patterns discovered from data. It can be aggregation and generalization of data, identification of frequent pattern and association rules, discovery of major patterns and themes as clusters, or a trained classification model that can make predictions or decisions.
These are ones related to major styles of machine learning.
However, data mining is not limited to these. There can be other patterns you hope to identify, such as the detection of outliers and exceptions, the trends and evolution, certain characteristics in a graph or network, and so on.

Data mining is an exciting field and there are so many potentials.