
Data Quality
- Today’s real-world data likely origins from multiple, heterogeneous sources
- Therefore, we are very likely to handle low-quality data
- It is important to properly address data quality issues
- Even simple descriptive analysis can be applied such that:
- Sort all values in ascending or descending order
- If all values are identical: no information. Ignore this variable!
- If some values occur abnormally with very high frequency (e.g., "Alabama" in 20% cases for state entry: need to examine whether it is caused by any interesting pattern (e.g., football fan survey) or error (e.g., default value)
- Sort all values in ascending or descending order
- All techniques (e.g., data cleaning, integration, reduction, transformation, and discretization) related to data quality need to be properly addressed
In this exercise, we are going to utilize a dataset distributed as a part of the Yelp Dataset Challenge (https://www.yelp.com/dataset). The ultimate goal is to create a classifier to predict the usefulness of each review by using various attributes. For instance, the count of words can be a good indicator of the usefulness of reviews because longer reviews can deliver more information than shorter reviews can do. The sentiment of reviews might be important because too positive/negative reviews might not be objective. Metrics related to social networks such as degree, betweenness, and eigenvector might be important by representing the social status of reviewers. To achieve the ultimate goal, preprocessing data is the first step. Let's open the data. There are 1,000 tuples and 26 attributes. The names of attributes are self-explanatory.
## Imports all necessary modules
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from numpy import linalg
from scipy import stats
## This loads the csv file from disk
yelp_data = pd.read_csv(
filepath_or_buffer = "./data/Yelp_Usefulness_Practice.csv", sep = ",", header=0 )
print(yelp_data.head(20))
## print the dimension of the data
print(yelp_data.shape)
## Set the maximum number of columns as "None" to display all columns
pd.set_option('display.max_columns', None)
## Pandas' describe method can provide basic statistics for numeric variables at default
print(yelp_data.describe())
## In the above, only 24 attributes got results.
## We need to select "only" categorical attributes to get descriptive statistics for categorical attributes
print(yelp_data[["review_id", "class"]].describe())
For the categorical attributes, we found that there are no cases such that all values are identical or some values occur abnormally with very high frequency.
However, in the case of numeric attributes, we found that there are three missing values in the "liking" attribute. The total count of tuples is 997, although all other attributes' count is 1,000. We can also check missing values by using Pandas' isna method. Also, "dislike" attribute has all zero values. That said, we need to drop this attribute by using Pandas' drop method. However, we will keep this for now.
## Show the number of data per attributes that has missing values
print(yelp_data.isna().sum())
## check the missing values across tuples of the "liking" attribute
print(yelp_data["liking"].isna())
Now, let's create a box plot to see the distribution of the "liking" attribute. This will help us to determine how to handle the missing data.
## Initialize a 6 x 6in figure
fig = plt.figure(figsize = (6, 6))
## Make the box plot
plt.boxplot(
## We beed to drop tuples that include missing values
yelp_data["liking"][~yelp_data["liking"].isna()], labels = ["Liking"]
)
## Adjust the tick and label font size
plt.tick_params(labelsize = 15)
## Set the title
plt.title("The normalized number of words related to 'liking' sentiment", fontsize = 15)

It seems that most of the values are zeros except for one tuple. It is skewed. Therefore, it might be better to use the median central tendency.
## We should exclude missing tuples to get median
median = np.median(yelp_data["liking"][~yelp_data["liking"].isna()])
print ("The median is: ", median)
## Replace missing values with median
yelp_data["liking"].fillna(median, inplace=True)
## Check whether the missing value were filled
print(yelp_data.isna().sum())
## The first attribute (review_id) and the last attribute (class) are categorical
## Therefore, we cannot calculate z-score
## The "dislike" attribute has 0 mean and sd. Therefore, we cannot calculate z score.
## We create indices that exclude review_id, dislike, and class
positions = list(range(1,13))
positions.extend(list(range(14,25)))
z = np.abs(stats.zscore(yelp_data.iloc[:, positions]))
print(z)
The above numbers represent z scores of our data. It is difficult to say which data point is an outlier. Let’s try and define a threshold to identify an outlier. To be conservative, we will use 3 as a threshold. We can exclude 0.3% of data.
threshold = 3
print(np.where(z > 3))
The first array contains the list of row numbers, and the second array corresponding column numbers that have a Z-score higher than 3, which mean they are: z[7][1], z[18][17], z[18][23], and so on.
We may want to remove tuples in which the most attributes are outliers. We can remove all tuples regardless of the number of attributes that are outliers. For this exercise, we adopt a very conservative approach. Therefore, we count the frequency of tuples that includes outliers.
unique_elements, counts_elements = np.unique(np.where(z > 3)[0], return_counts=True)
print(np.asarray((unique_elements, counts_elements)))
The first list represents the row number when the z score is larger than 3. The second list represents the frequency of the corresponding row. The row 69 and 262 have the largest number of outliers. Therefore, we want to remove these tuples from the dataset.
yelp_data = yelp_data.drop([ 69, 262])
print(yelp_data.shape)
As you can see, two tuples were dropped. I will leave outlier detection exercise using IQR to you.
pcorr = yelp_data.corr(method='pearson')
## Set the maximum number of columns as "None" to display all columns
pd.set_option('display.max_columns', None)
pcorr
It is hard to see. We can use a heatmap to visualize the correlation coefficients.
plt.figure(figsize=(12,10))
sns.heatmap(pcorr, annot=True, cmap=plt.cm.Reds)
plt.show()

We found the strongest correlation (0.94) between degree and eigenvector. The degree and betweenness are also strongly correlated (0.83). These results represent redundancies in attributes. We can drop one or two of them. However, we will leave it to the feature subset selection method in this exercise.
Data Integration 2
One common challenge in data integration is attribute construction. New attributes need to be constructed from the given ones if existing attributes do not adequately reflect the target label/value. For instance, the "area" is a better indicator of housing prices than the "length" and "width" of a house. We observed that attributes related to sentiment are sparse. Most of them are zeros. We will create new attributes from the given ones. The attributes in the left of the arrow mark are existing ones, and the attributes in the right are new ones.
- joy, love, affection, liking, enthusiasm -> positive_emotion
- sadness, dislike, despair, horror, distress -> negative_emotion
yelp_data["positive_emotion"] = yelp_data["joy"] + yelp_data["love"] + yelp_data["affection"] + yelp_data["liking"] + yelp_data["enthusiasm"]
yelp_data["negative_emotion"] = yelp_data["sadness"] + yelp_data["dislike"] + yelp_data["despair"] + yelp_data["horror"] + yelp_data["distress"]
## Drop existing attributes
yelp_data = yelp_data.drop(["joy", "love", "affection", "liking", "enthusiasm", "sadness", "dislike", "despair", "horror", "distress"], 1)
print(yelp_data.head())
Dimensionality Reduction + Normalization
As a method of data reduction, we can apply dimensionality reduction. We covered PCA and feature subset selection in the lecture. In this exercise, we will cover feature subset selection. We are also going to apply normalization before selecting a feature subset. We will implement the forward selection and bi-directional stepwise selection.
## Create feature matrix by dropping the review_id and label attribute
## Review_id is not going to helpful to predict the usefulness of reviews
X = yelp_data.drop(["review_id","class"], 1)
## Pre-processing. Sklearn takes integer as label
# ## Create target attribute
yelp_data[yelp_data['class'] == 'useful'] = 1
yelp_data[yelp_data['class'] == 'not_useful'] = 0
# ## Specify the data type. Before specifying, the type was unknown
y = yelp_data["class"].astype('int')
print(yelp_data["class"])
print(X.shape[1])
## import the necessary libraries
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.naive_bayes import MultinomialNB
from sklearn import preprocessing
## Apply Min_Max Scaler
min_max_scaler = preprocessing.MinMaxScaler()
X_minmax = min_max_scaler.fit_transform(X)
X_minmax = pd.DataFrame(X_minmax)
## Sequential Forward Selection(sfs)
## Please refer to http://rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector/#sequential-feature-selector
## for the detailed arguments options
sfs = SFS(MultinomialNB(),
k_features=(1,X_minmax.shape[1]),
forward=True,
floating=False,
scoring = 'r2',
cv = 10)
sfs.fit(X, y)
## Get the final set of features
sfs.k_feature_names_
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
import matplotlib.pyplot as plt
## performance graph (y-axis: r-squared values)
fig = plot_sfs(sfs.get_metric_dict(), kind='std_dev')
plt.title('Sequential Forward Selection (w. StdErr)')
plt.grid()
plt.show()
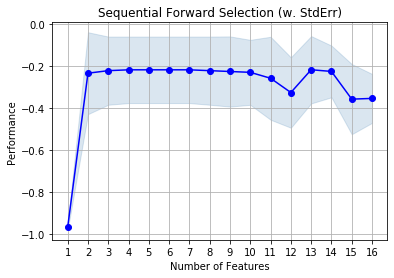
Thirteen attributes were selected. Let's try bi-directional stepwise selection (combination of forward and backward selection) and compare results.
## Bi-directional stepwise selection
## Please note that floating option was changed to "True"
sfs1 = SFS(MultinomialNB(),
k_features=(1,X_minmax.shape[1]),
forward=True,
floating=True,
scoring = 'r2',
cv = 10)
sfs1.fit(X, y)
# Get the final set of features
sfs1.k_feature_names_
## performance graph (y-axis: r-squared values)
fig1 = plot_sfs(sfs1.get_metric_dict(), kind='std_dev')
plt.title('Sequential Bi-directional Stepwise Selection (w. StdErr)')
plt.grid()
plt.show()
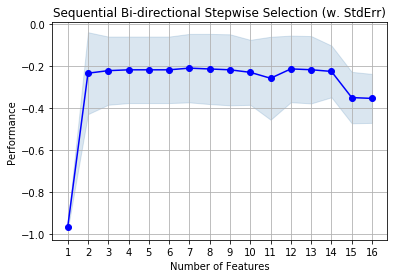
Now, we have seven attributes ('review_stars','word_count','correct_spell_ratio','price_included','eigenvector','positive_emotion','negative_emotion'). We have a reduced set of attributes. The performance from both selection methods seems to be not very different. Potentially, using a small set will be better if the performance is not very different? However, it is still early to conclude. We did not separate data into training and testing sets. Also, what is the goal of your classifier? Is it effectiveness or efficiency? Usually, we need to sacrifice one to achieve another. In other words, effectiveness increases when efficiency decreases, and vice versa. We will cover these topics later.