
Introduction
- Clustering is a process of grouping a set of data objects into multiple groups or clusters so that objects within a cluster have high similarity, but are very dissimilar to objects in other clusters.
- There are a lot of areas to apply cluster analysis, such as collaborative filtering, outlier detection, and dynamic trend detection.
- In this exercise, we will practice with topic clustering. In other words, we will group documents by topic to support navigation and exploration.
- If you have not done yet, please review the text vectorization exercise: http://keensee.com/pdp/demo/python_text_vector.html.
In this exercise, we are going to utilize a dataset distributed as a part of the Yelp Dataset Challenge (https://www.yelp.com/dataset). This is the same dataset you used for the data preprocessing and assignment 2. The previous dataset had attributes processed from text, while it did not include text. In this exercise, you would directly process text. Let's open the data. There are 1,000 tuples and 4 attributes. The names of attributes are self-explanatory: review_id, text, categories, and class. You are going to work with the text attribute.
## Imports all necessary modules
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import nltk, re
# Sklearn
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn import metrics
from pprint import pprint
## This loads the csv file from disk
yelp_data = pd.read_csv(
filepath_or_buffer = "yelp_reviews.csv", sep = ",", header=0 )
print(yelp_data.head(20))
## print the dimension of the data
print(yelp_data.shape)
# Convert text to a list of data
data = yelp_data.text.values.tolist()
# Created a list of ids
ids =yelp_data.review_id.values.tolist()
# Remove new line characters
data = [re.sub('\s+', ' ', sent) for sent in data]
pprint(data[:5])
## Conduct text preprocessing such as tokenization, stopwords removal, and stemming.
from nltk.tokenize import word_tokenize
## tokenization
tokens = [word_tokenize(review) for review in data]
print(tokens[:5])
## import NLTK stopwords
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
## following punctuations and contractions do not deliever any special meaning in text processing.
stop_words.extend(["!", ".", ",", "?", "'", "-", "(", ")", "'s", "'ve", "'m" ])
## remove stopwords
tokens_no_stopwords = [[word.replace("'","") for word in review if word not in stop_words] for review in tokens]
print(tokens_no_stopwords[:5])
## load nltk's SnowballStemmer
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("english")
## stemming and normalization by converting all characters to lower cases
tokens_stemmed = [[stemmer.stem(word) for word in review] for review in tokens_no_stopwords ]
print(tokens_stemmed[:5])
## concatenate tokens
## the input for vectorizer should be in the form of a list of string
tokens_concatenated = [" ".join(token) for token in tokens_stemmed]
print(tokens_concatenated[:5])
##define vectorizer parameters
tfidf_vectorizer = TfidfVectorizer(
analyzer = 'word',
max_df=0.8,
max_features=2000,
min_df=0.05,
stop_words='english',
use_idf=True,
ngram_range=(1,3),
token_pattern='[a-zA-Z0-9]{3,}', # num chars > 3
)
tfidf_matrix = tfidf_vectorizer.fit_transform(tokens_concatenated)
print(tfidf_matrix.shape)
terms = tfidf_vectorizer.get_feature_names()
## print features you selected.
print(terms)
## it is useful to know what terms are included. But knowing the real tf-idf values will be more helpful
review_index = [n for n in ids]
import pandas as pd
df = pd.DataFrame(
tfidf_matrix.T.todense(), index=terms, columns=review_index)
print(df.transpose())
Great! You have applied text preprocessing and created a tf-idf term matrix so far. As you can see, there are a few parameters you can modify in the TfidfVectorizer, such as max_df and min_df. If a term occurs too much, then the term is not unique enough to deliver any information. These are terms such as stopwords. Also, if a term rarely occurs, then the term does not have enough evidence to prove to be discriminative. Therefore, changing these parameters would give you different tf-idf matrices. Especially, the number of terms will change. For details, please look at the documentation: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
K-means clustering
Now, we are ready to move onto the next fun step, which is the actual clustering using K-means algorithm. Please note that you should specify the number of clusters (k) to the algorithm in advance. Also, this algorithm finds a local optimum instead of a global optimum. Therefore it is wise to run the k-means algorithm multiple times with different k. We will practice this in the later part.
from sklearn.cluster import KMeans
## specify K
num_clusters = 5
km_model = KMeans(n_clusters=num_clusters)
km_model.fit(tfidf_matrix)
## retrieve cluster ids
clusters = km_model.labels_.tolist()
print(clusters)
Now you can see the cluster id of each review. However, this simple number does not deliver much information useful for you to understand the results. Therefore it might be useful if you could get representative words for each topic (i.e., cluster id) and the distribution of topics.
## Create Pandas dataframe by using the following dictionary
review = { "review_id" : ids, 'cluster': clusters }
result = pd.DataFrame(review, index = [ids] , columns = ['cluster'])
print(result)
# Review topics distribution across reviews
df_topic_distribution = result['cluster'].value_counts().reset_index(name="Num Reviews")
df_topic_distribution.columns = ['Topic Num', 'Num Reviews']
print(df_topic_distribution)
from __future__ import print_function
print("Top terms per cluster:")
print()
# Sort cluster centers by proximity to centroid
order_centroids = km_model.cluster_centers_.argsort()[:, ::-1]
# Set the number of top keywords for each cluster
num_top_keywords = 15
for i in range(num_clusters):
print("Cluster %d top keywords:" % i, end='')
print() #add whitespace
for ind in order_centroids[i, :num_top_keywords]:
print(terms[ind])
print() #add whitespace
After reviewing top keywords for each cluster, it seems that cluster 0 is about hotels, cluster 1 is about clubs or bars, and cluster 2 to 4 is about restaurants. This result makes sense because most reviews in Yelp are for restaurants. Then, now it is going to be important to find the best k for clustering because we simply assume that 5 might be a good number of clusters. We will do it by using Silhouette measure, which is an intrinsic measure you learned in the lecture.
from sklearn.metrics import silhouette_score
sil = []
kmax = 20 ## change this value as necessary
## dissimilarity would not be defined for a single cluster, thus, minimum number of clusters should be 2
## increase the number of K from 2 to 20
for k in range(2, kmax+1):
kmeans = KMeans(n_clusters = k).fit(tfidf_matrix)
labels = kmeans.labels_
sil.append(silhouette_score(tfidf_matrix, labels, metric = 'euclidean'))
K = range(2, kmax+1)
plt.plot(K, sil, 'bx-')
plt.xlabel('k')
plt.ylabel('Silhouette score')
plt.title('Silhouette Method For Optimal k')
plt.show()
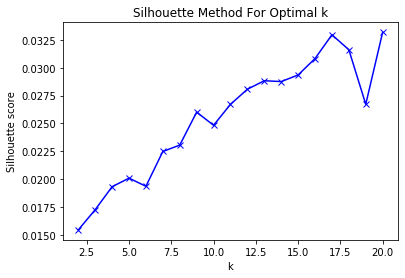
So, it seems that k = 17 or 20 seems to create the best cluster. However, you will have different results for every run, because K-means algorithm depends on the random initial seeds. Also, there are a lot of other measures, and they might make a different prediction. To see other measures, please refer to the following documentation: https://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_digits.html#sphx-glr-auto-examples-cluster-plot-kmeans-digits-py
Bottom-up method
Now it is time to practice another clustering algorithm. I will leave this to you. As mentioned in the lecture, K-means clustering is sensitive to noisy data. According to Zipf's law, text distribution is usually very skewed, which means a lot of outliers. Perhaps, K-means algorithm might not be the best algorithm for topic clustering. Agglomerative hierarchical clustering aims at finding the best step at each cluster fusion, and our data might have an intrinsic hierarchy in it. Think about the category of restaurants. It might starts from Western vs. Eastern. Eastern might have sub-categories such as Korean, Indian, Chineses, Japanese, and so on. If the data has a hierarchy like this, probably hierarchical clustering might be a better choice. Go for it and see whether it really makes any difference. Please see the following link for implementation: https://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering